-
Guillaume BRUNEVAL,
-
Data scientist
Publié le 17/09/2020
Juin 2018, l’éditeur DataBricks annonce la sortie de son dernier-né : MLFlow. Depuis, le framework a fait du chemin et conquis nombre d’adeptes parmi les équipes de Data Science. Mais que se cache-t-il derrière ce nom composé d’un acronyme, ML pour Machine Learning, et d’un mot devenu très générique, Flow ? Cela vous semble encore obscur. Pas de panique, Kernix s’est penché sur la question et vous propose quelques explications.
Un projet de Machine Learning consiste, en étant très générique, en l’application d’une méthode théorique à un jeu de données particulier. Le travail d’une équipe de Data Science est, là encore très schématiquement, de sélectionner la méthode la plus performante avec les paramètres qui lui permettront de s’adapter au mieux aux données en présence. Et pour se faire, les connaissances théoriques et l’intuition, aussi géniale puisse-t-elle être, ne suffisent pas. Il faut faire des essais, des tests, des expériences. Une des difficultés majeures rencontrée dans tous les projets de Machine Learning est de conserver une trace de chaque expérience afin de reproduire celles qui ont fourni les meilleurs résultats.
Mettons nous en situation. Imaginons que nous travaillons dans un laboratoire de recherche médical. Notre mission consiste à venir en aide aux diabétiques en prédisant l’évolution de leur pathologie sur l’année à venir afin que l’équipe médicale en charge de son suivi puisse prescrire le traitement le plus adapté. Nous avons eu accès à un grand nombre de données, sur des patients atteints dans le monde entier ces dernières années, et, par chance, nous connaissons leur état de santé actuel et pouvons mesurer l’avancement de leur diabète à l’aide d’un indicateur chiffré que nous avons mis en place.
Nous décidons d’appliquer plusieurs pré-traitements aux données nous tenons compte de certaines variables dans un premier temps puis décrétons finalement d’en oublier certaines qui n’étaient pas pertinentes et d’en incorporer d’autres nous testons plusieurs types d’algorithmes, avec de nombreux réglages de paramètres différents nous produisons des visualisations claires. Bref, nous travaillons avec acharnement et avons mené un très grand nombre d’expériences, parfois plusieurs de front, parfois avec des collègues, parfois seul. Et il nous est arrivé parfois d’obtenir de très bonnes prédictions. On est donc assez confiant et assuré de pouvoir révolutionner le suivi du diabète dans les prochaines années.
Arrive le jour où il faut se lancer, un malade et son médecin font appel à nous pour prédire l’avancement du diabète du patient dans un an. Là, nous voudrions naturellement appliquer la meilleure stratégie et retrouver le modèle le plus performant, avec les paramètres optimaux. Alors nous espérons fiévreusement que nous, et chacun des membres de l’équipe, ayons eu la rigueur et la présence d’esprit de consigner clairement et soigneusement les résultats de chaque expérience. Il vaudrait également mieux que ces informations soient suffisamment bien organisées, dans des formats à peu près similaires pour pouvoir les concentrer et les comparer méthodiquement, sinon, on risque d’y passer un peu de temps…
Fort heureusement, dans l’écosystème foisonnant des Framework de Machine Learning, il en est un qui nous épargnera ces sueurs froides, et il a le bon goût d’être open source. Développé par « Databricks », la plateforme MLFlow va nous permettre de gérer notre projet de Machine Learning tout au long de son cycle de vie.
MLFlow se propose de répondre à trois préoccupations majeures des équipes de data-science :
En réponse à ces trois problématiques, MLFlow s’est construit sur trois composants principaux qui apparaissent comme ses piliers :
MLflow Models : MLFlow accepte toute les technologies, tous les outils. MLFlow Models vous permet de déployer votre modèle aussi bien sur Docker que sur Azure ML ou encore Apache Spark.
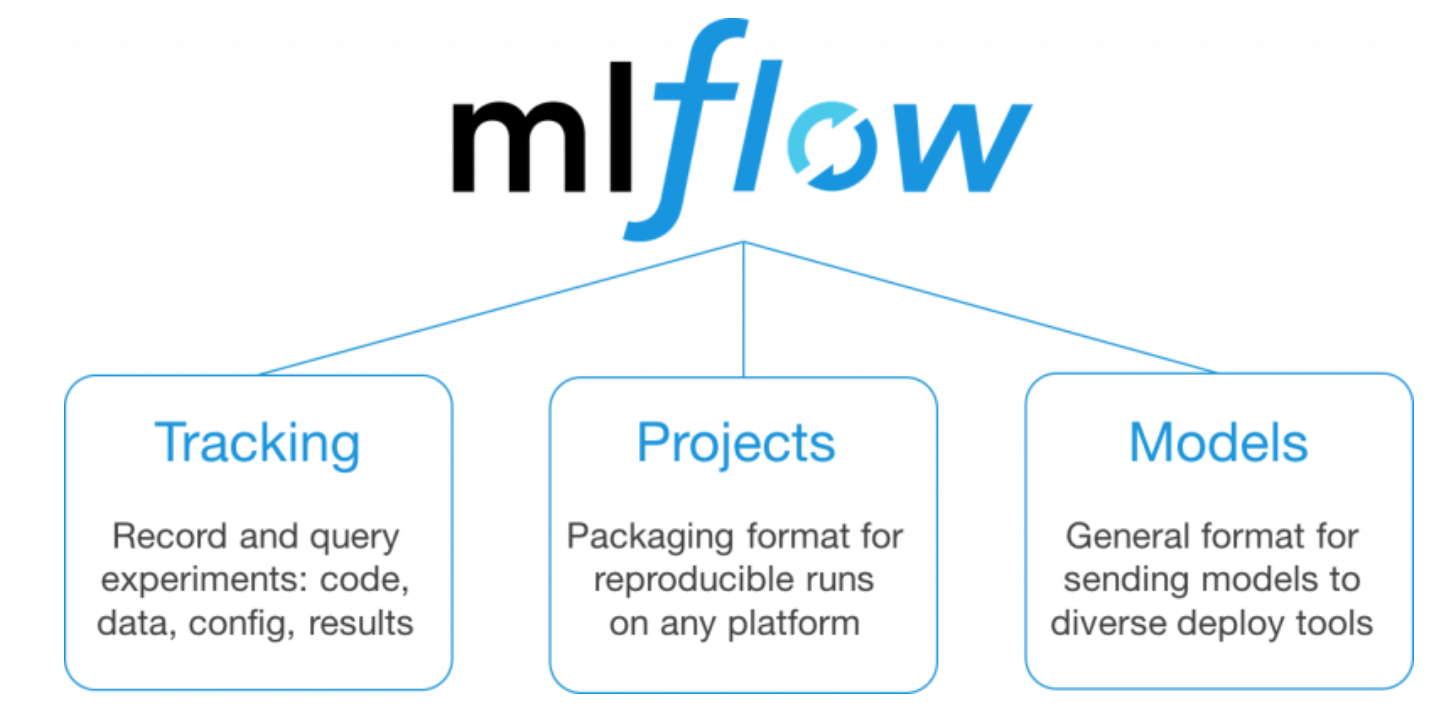
Les trois piliers sur lesquels repose MLFlow.
De ces trois piliers, ce premier article sur le blog Kernix au sujet de MLFlow vous propose d’en explorer le tracking qui est celui que nous utilisons majoritairement dans nos projets.
Parmi la pléthore d’outils qui émergent pour la gestion des projets de Machine Learning, nous avons choisi de vous présenter MLFlow et en particulier MLFlow Tracking. Pourquoi ? Parce que MLFlow Tracking est simple. Simple à installer, simple à intégrer dans le code, simple à utiliser en interface graphique.
Quoi de mieux qu’une démonstration par l’exemple pour expérimenter ensemble la simplicité de cet outil ? Reprenons donc l’exemple d’introduction pour montrer certaines fonctionnalités de base. À partir d’un jeu de données public très connu sur des personnes atteintes du diabète, nous avons construit un modèle de régression pénalisée qui permet de prédire le degré d’évolution de la maladie d’ici un an.
Avant de commencer à utiliser l’API Tracking, décrivons un peu plus précisément notre modèle :
Nous cherchons à prédire un score d’évolution de la maladie à partir de dix variables : l’âge, le sexe, l’indice de masse corporelle, la pression ainsi que six autres mesures sanguines. Notre algorithme est une régression « Elastic-Net » sur laquelle nous choisissons de faire varier deux (hyper)paramètres nommés « alpha » et « l1-ratio ». Nous choisirons, par ailleurs, d’étudier les performances de notre modèle à partir de deux mesures, appelées « métriques », qui calculeront la proximité de nos prédictions avec les résultats dont nous disposons. Ces deux métriques seront nommées respectivement « MSE » et « R2 ».
Récapitulons : Nous allons faire varier « alpha » et « l1-ratio » et voudrions trouver pour quelle combinaison de ces deux valeurs, on obtient les meilleurs résultats. Pour rendre notre travail plus lisible nous nous concentrerons ici sur la valeur de MSE, laquelle doit être la plus petite possible.
Ces précisions apportées, nous pouvons commencer à utiliser l’API Tracking.
On ouvre un terminal et on installe MLFlow à l’aide de l’instruction :
pip install mlflow
On ouvre ensuite l’environnement Python de son choix (dans notre cas il s’agit de Jupyter Notebook).
import mlflow
import logging
logging.basicConfig(level=logging.WARN)
logger = logging.getLogger(__name__)
On importe les bibliothèque MLFlow.
On se place dans une « expérience » :
mlflow.set_experiment("ml_flow_Essai")
Cette instruction sert à créer une « expérience » qu’il faut nommer d’un nom unique. C’est avec ce nom que l’on accèdera ultérieurement à cette expérience à l’aide de la même commande.
Pour démarrer une session nommée ‘Elastic_net’ on utilise l’instruction :
mlflow.start_run(run_name='Elastic_net')
On construit ensuite notre modèle et on prépare les valeurs de paramètres que l’on souhaite tester.
Pour conserver une trace de nos test, on utilise essentiellement ces deux instructions :
# On indique à MLFlow de consigner les paramètres...
mlflow.log_params({'alpha':a, 'l1_ratio':r})
# ... et les résulats correspondants
mlflow.log_metrics({'MSE':mean_squared_error(y_pred, y_test),
'R2':r2_score(y_pred, y_test)})
Récapitulons les étapes précédentes dans le code ci-dessous :
# import des librairies
from sklearn.linear_model import ElasticNet
from sklearn.model_selection import train_test_split
from sklearn import datasets
from sklearn.metrics import mean_squared_error, r2_score
import mlflow
import mlflow.sklearn
import logging
logging.basicConfig(level=logging.WARN)
logger = logging.getLogger(__name__)
# demarrage d'une "expérience"
mlflow.set_experiment("ml_flow_Essai")
#chargement des données
X, y = datasets.load_diabetes(return_X_y=True)
# on sépare le jeu de données
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=123)
# on normalise les données
X_train_norm = (X_train-np.mean(X_train))/np.std(X_train)
y_train_norm = (y_train-np.mean(y_train))/np.std(y_train)
X_test_norm = (X_test-np.mean(X_train))/np.std(X_train)
# On créer une liste de valeurs à tester pour chaque paramètre
r_list = [0.1*i for i in range(11)]
a_list = np.logspace(-5, 1, 30)
# On boucle sur les liste
for r in r_list:
for a in a_list:
# on ouvre une session mlflow
with mlflow.start_run(run_name='Elastic_net'):
#On spécifie le modèle
reg = ElasticNet(alpha=a, l1_ratio=r, fit_intercept = False, max_iter = 1000)
#On entraîne le modèle
reg.fit(X_train_norm, y_train_norm)
#On prédit sans oublier de dénormaliser
y_pred = reg.predict(X_test_norm)*np.std(y_train)+np.mean(y_train)
# On indique à MLFlow de consigner les paramètres...
mlflow.log_params({'alpha':a, 'l1_ratio':r})
# ... et les résulats correspondants
mlflow.log_metrics({'MSE':mean_squared_error(y_pred, y_test),
'R2':r2_score(y_pred, y_test)})
Il ne s’agit pas ici de déchiffrer l’ensemble du code, mais de comprendre que, par rapport à une manière de travailler classique, l’intégration de MLFlow n’a nécessité que cinq lignes de code supplémentaires. Voyons maintenant ce que ces cinqlignes de code nous permettent de faire.
On reprend notre terminal et on exécute la commande : mlflow.ui .

Rendons-nous maintenant dans notre navigateur et accédons à l’adresse “localhost:5000”.
Nous arrivons alors sur l’interface MLFLow.
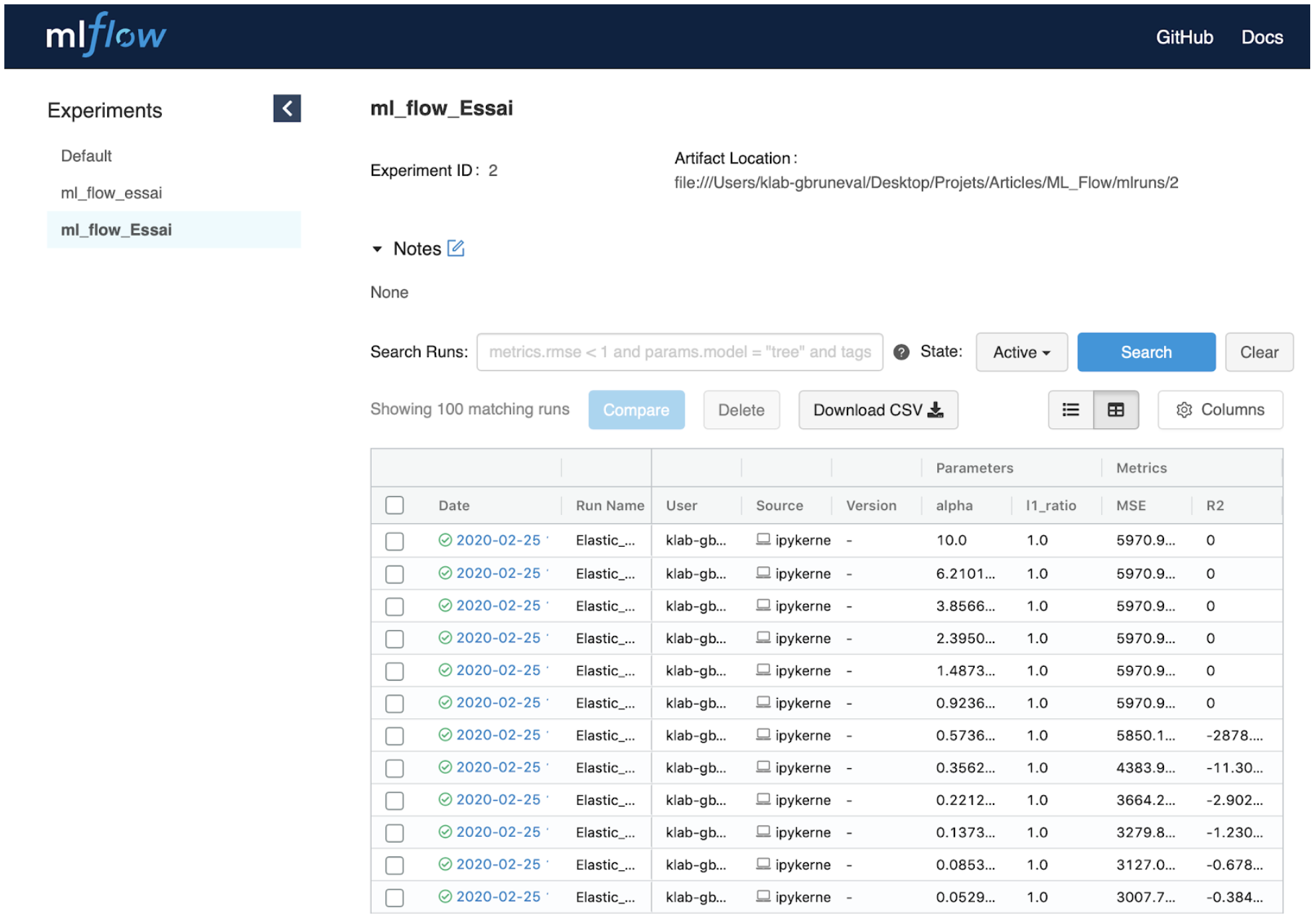
Tous nos test apparaissent avec les valeurs des paramètres et des métriques correspondantes.
Cependant, nous avons testé 300 combinaisons de valeurs, ce qui rend l’étude des résultats fastidieuse. Heureusement, MLFlow est d’une aide précieuse. Le bouton « comparer » permet d’accéder à des visualisations sous forme de tableaux et de graphiques qui permettent de comparer rapidement les résultats :
Nos visualisations sont un peu confuses. Trois cents points, cela peut être un peu pénible à observer.
Heureusement, on peut se servir d’un champ de saisie pour émettre une requête et affiner notre recherche : On est parvenu à cerner que les meilleurs résultats produisaient une MSE autour de 2900 et qu’ils ont été obtenus pour une valeur de l1-ratio égale à 1. On écrit donc la requête ci-dessous :
On peut ensuite lancer une nouvelle comparaison :
Cette deuxième visualisation nous permet de cerner la combinaison optimale qui est l1_ratio =1.0 et alpha = 0.020433597… Il faut néanmoins bien avouer que nous obtenons une valeur de MSE qui demeure bien éloignée de ce qu’elle pourrait être, ce qui prouve, s’il en est besoin, que la recherche d’un modèle performant nécessite qu’on y passe un peu de temps.
Nonobstant la perfectibilité de nos résultats, cette courte démonstration par l’exemple vous aura convaincu, je l’espère, de l’utilité et de la facilité de prise en main d’un outil qui devrait continuer à faire parler de lui.
