Publié le 18/11/2021
Data Science
Les packages, le formalisme idéal pour industrialiser du code Python
Les data scientists ont pris pour habitude d’utiliser des notebooks, mêlant ainsi code, visualisations et texte détaillant l’analyse des résultats et la compréhension des données. Un notebook permet de produire un rapport complet, dont toutes les étapes peuvent être reproduites en exécutant le code du notebook. Bien que cette nouvelle forme de développement présente de nombreux avantages dans le cas de la data science, il est judicieux de passer à une autre forme lors d’une mise en production, et même au cours de la modélisation : packager le code offre des garanties appréciables. Bien souvent, hélas, le passage à l’industrialisation consiste à extraire des fonctions et des variables globales qui sont concaténées dans un ou plusieurs fichiers Python placés dans un répertoire.
Chez Kernix, notre vocation est d’industrialiser nos réalisations en data science. De ce fait, il est indispensable que nos livrables (code source) soient packagés de manière à :
- faciliter la maintenabilité et l’évolutivité ;
- garantir un haut niveau de performance et de sécurité ;
- tracer et logger tout dysfonctionnement.
Du notebook aux modules
Les notebooks caractérisent une nouvelle façon de développer utilisée par les data scientists. Ils favorisent la recherche reproductible qui consiste à pouvoir reproduire intégralement un article de recherche : les résultats d’une analyse de données, par exemple des statistiques descriptives, peuvent être calculées à partir d’un code ; les commentaires accompagnant l’analyse sont inclus au sein d’un même document et constituent ainsi, ce qu’on appelle un notebook. Le notebook peut ainsi être partagé à quiconque souhaite reproduire l’analyse, éventuellement en changeant les données.
La plupart des projets de data science commencent avec un notebook qui s’enrichit au fil des journées par des éléments d’exploration de données et des premiers tests de modélisation. Un notebook peut donc devenir très volumineux, d’autant plus que l’étude sera longue. Il est alors souhaitable de pouvoir avoir une vision plus globale en cachant certains détails d’implémentation.
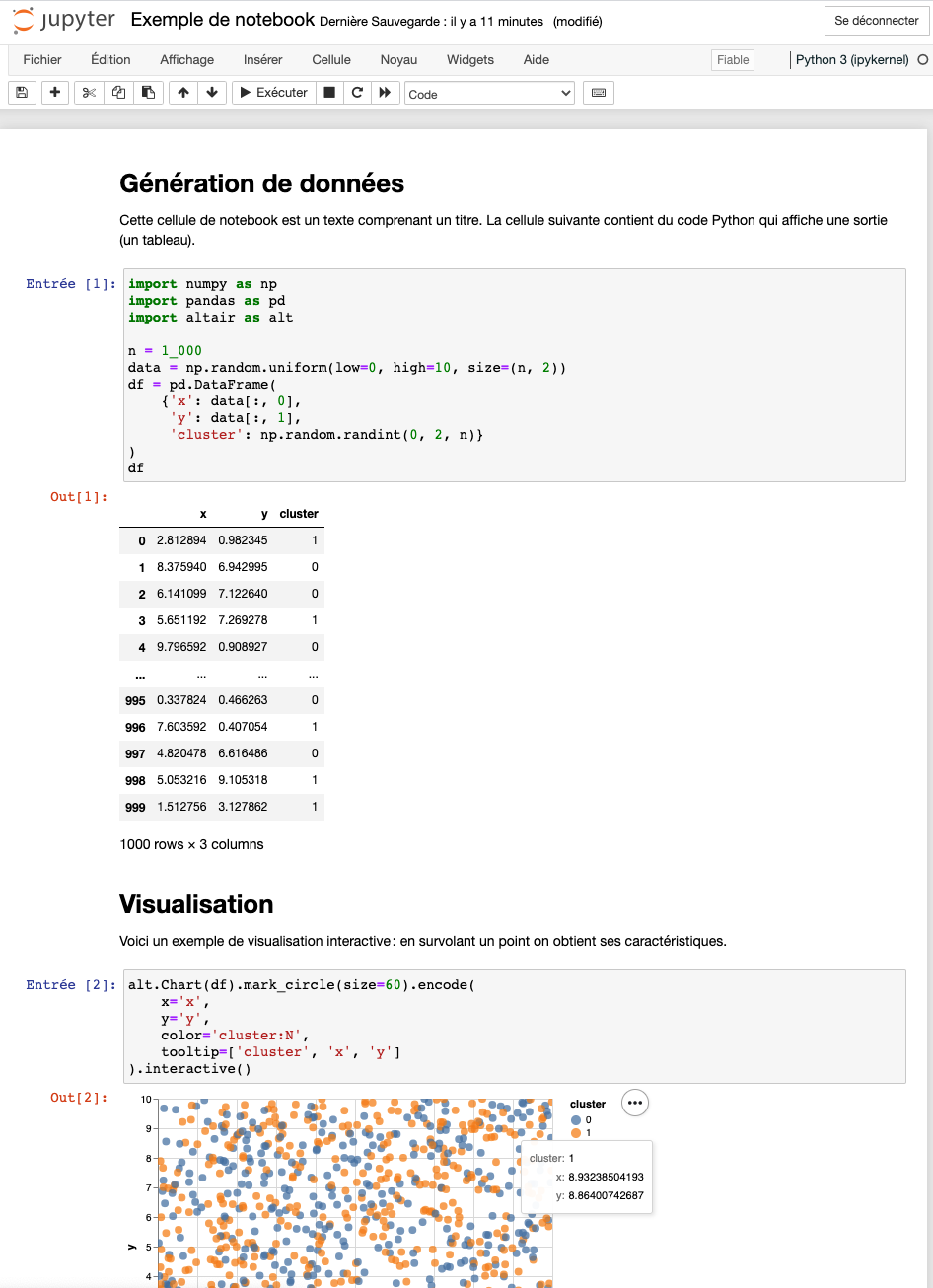
Création de fonctions
Le premier niveau d’abstraction est ce qu’on appelle une fonction. Il s’agit d’un code qui s’exécute lorsque le nom de la fonction est appelé. Une bonne pratique issue de la programmation fonctionnelle est de faire en sorte que le résultat de la fonction dépende uniquement des arguments passés à la fonction.
Création de modules
Pour organiser davantage le code et ajouter un niveau d’abstraction, la création de modules permet de le séparer en différents fichiers. Chaque module ou fichier est alors constitué d’un ensemble de fonctions qui constituent un ensemble cohérent. Par exemple, pour la création d’un système de recommandation, un module peut regrouper toutes les fonctions de prétraitement des données et un autre, les fonctions permettant la recommandation.
Clarté du notebook
Les modules ainsi constitués sont séparés du notebook. Il est alors possible d’importer les fonctions des différents modules dans le notebook. L’ensemble des lignes de code qui constituent le corps de la fonction est présent dans le module séparé et seul l’appel de la fonction est à mettre dans le notebook. Il en résulte un notebook plus clair et concis, car les détails d’implémentation sont déportés dans les modules.
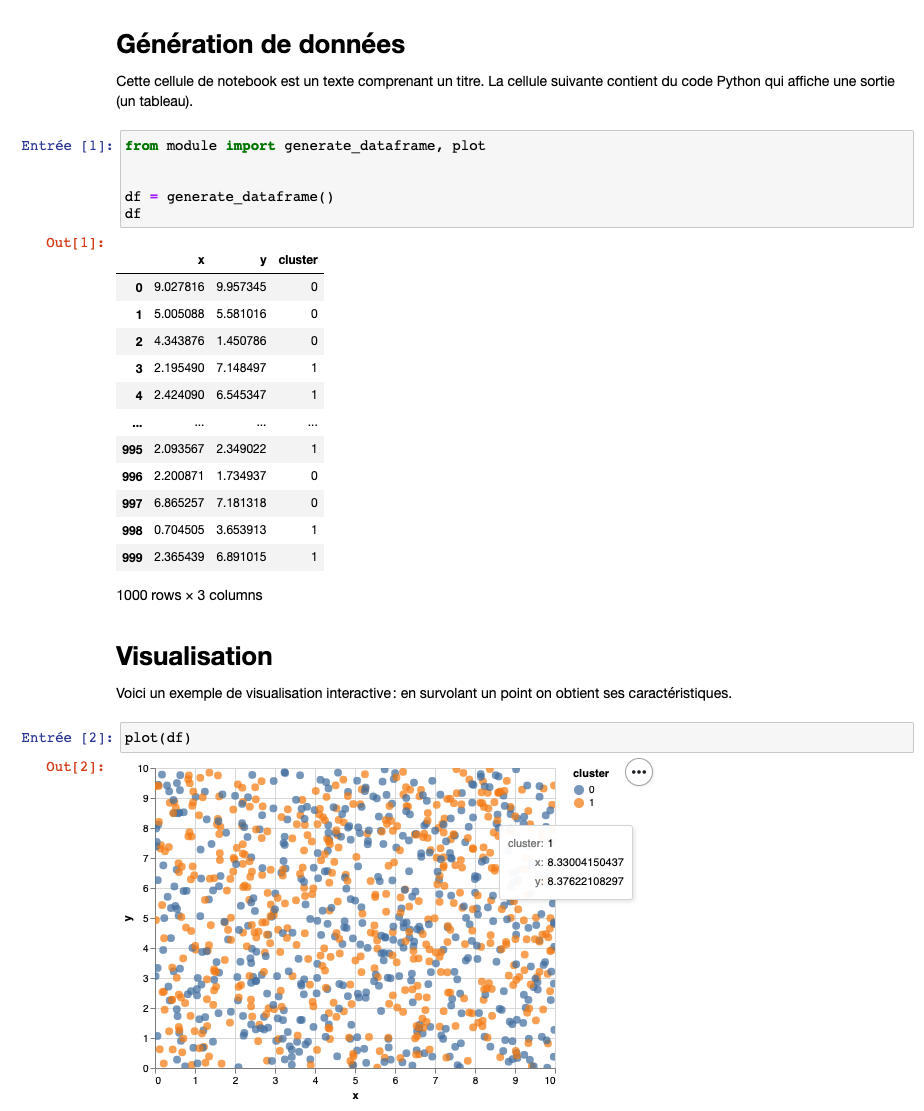
IDE
Un autre avantage de la création de modules est de pouvoir utiliser un environnement de développement intégré (IDE) autre que celui, très simple, lié à l’exécution du notebook (jupyter notebook par exemple). L’IDE permet de détecter plus facilement les bugs et propose des outils facilitant la création de code (auto-complétion, documentation des fonctions utilisées, etc.).
Des modules au package
Les packages (en Python, les autres langages offrant des fonctionnalités similaires peuvent utiliser un nom différent) permettent de regrouper différents modules.
Hiérarchie
L’intérêt de pouvoir regrouper différents modules est de créer une hiérarchie de modules. Par exemple, on peut créer un package regroupant les fonctionnalités de prétraitement qui est constitué de plusieurs modules : un pour traiter les textes et un autre pour les images. Celui pour les textes peut se transformer en package et avoir plusieurs modules pour regrouper les différentes étapes de traitement du texte.
Appels depuis un autre dossier
Une autre notion, également appelée package en Python (il s’agit plus précisément de « distribution package » tandis que le paragraphe précédent discutait de « import packages ») permet de créer une bibliothèque.
Utilisation en tant que bibliothèque
Une bibliothèque, une fois installée, peut être utilisée depuis n’importe quel code Python. L’avantage est de pouvoir utiliser la même bibliothèque dans le notebook servant à l’exploration des données et le développement d’un modèle de machine learning, et dans un code applicatif (par exemple un moteur de recommandation en production). Sans cela, la manière de fonctionner de Python fait qu’il serait quasiment obligatoire (pour éviter d’autres problèmes, de collision de noms par exemple) d’avoir aussi bien les modules que le code les utilisant au même niveau.
La gestion rigoureuse des « effets de bords » (lecture et écriture de fichiers par exemple) est nécessaire lors de la création de bibliothèque puisque la bibliothèque n’a pas le contrôle de l’endroit où elle est exécutée.
Tests
Isoler les fonctionnalités dans un package installable permet de les tester plus facilement. Les tests s’exécutent dans un environnement différent, assurant qu’aucune variable globale créée ou modifiée par une fonction ne perturbe son fonctionnement normal. Ils permettent de reproduire le plus fidèlement possible l’utilisation réelle dans des conditions variées.
Environnements virtuels
Pour isoler l’application et ses dépendances des autres applications tournant sur le système, des environnements virtuels peuvent être créés. Python permet d’installer dans un dossier toutes les dépendances (autres bibliothèques Python) du package, d’activer l’environnement de manière à ce que le projet aille chercher ses dépendances dans le dossier ainsi créé seulement. De cette manière, il n’y a aucune interférence entre le projet et les autres applications installées sur le système. Ce système d’environnement virtuel permet de garantir que toutes les dépendances sont définies dans le script d’installation, et donc que le code sera facilement déployable sur tout nouveau serveur. Ils permettent aussi de tester le changement de version de Python ou de toute dépendance très facilement.
Dépendances
Lors de la création d’un package, les dépendances peuvent être définies explicitement. Ainsi, il n’y aucune mauvaise surprise lors d’un déploiement en production puisque les dépendances sont identiques à celles définies dans le package.
Documentation
Enfin, un package n’est rien sans sa documentation. À partir du code source documenté, il est très facile d’extraire les commentaires de documentation (appelés docstrings) pour générer une documentation complète. Ceci est rendu possible par la découverte des différents éléments (modules, fonctions, classes, etc.) du package. Les exemples de la documentation peuvent aussi être testés automatiquement lors de la génération de la documentation. De la même manière, les annotations de types (qui déclarent le type des paramètres et retours de fonctions) sont vérifiées automatiquement (l’annotation de type est optionnelle en Python, mais nous les utilisons systématiquement à Kernix pour détecter au plus tôt les erreurs potentielles et faciliter la reprise du code par un développeur).
Points d’entrées – Exécutables
Packager une application, c’est aussi définir des points d’entrées clairement identifiés. Ceux-ci appellent les autres fonctions définies dans le package afin d’exposer toutes les fonctionnalités. Ces points d’entrées peuvent être des exécutables en ligne de commande pour qu’un utilisateur puisse l’utiliser sans avoir besoin de connaître le langage Python ou bien un serveur web pour rendre accessible les fonctionnalités à partir d’appels HTTP. Cette dernière option est très utilisée par l’approche de développement en microservices, ce qui favorise une intégration au système d’information des entreprises.
Le développement d’applications packagées avec une documentation générée automatiquement, l’utilisation de bonnes pratiques, l’exposition des fonctionnalités par des interfaces claires, etc., fait partie des standards de Kernix. La data science et la création de PoCs ne justifient pas un sacrifice de qualité de développement, au contraire : le packaging permet de converger plus vite vers une solution qui répond aux enjeux métier tout en permettant l’intégration poussée au sein de tout type de système. La mise en production est considérée dès le début de projet, sans compromis entre la rapidité de développement et la qualité.
