Publié le 04/05/2020
Data Science
R 4.0: du POC à la mise en production
La version 4.0 du langage R vient de sortir. C’est l’occasion pour nous de présenter le riche écosystème de ce langage. Souvent mal aimé des SI, jugé hâtivement comme non adapté à la mise en production, R est pourtant un langage plein de qualités pour la création de POCs, et une bonne maîtrise de son fonctionnement permet de transformer des POCs en de véritables produits opérationnels.
Un langage pour la data science
R est historiquement un langage de programmation tourné vers les statistiques computationnelles et la science des données. Ainsi les données tabulaires peuvent être stockées dans une structure native, les data frames, et de nombreuses fonctions statistiques font partie de la bibliothèque standard. Les données peuvent être manipulées grâce à une bibliothèque devenue incontournable : dplyr. Cette bibliothèque définit une grammaire pour leur manipulation avec une API très expressive, consistante et efficace. Autour de cette bibliothèque, l’auteur prolifique Hadley Wickham a construit tout un framework, tidyverse. Les packages composant ce framework partagent la même philosophie et les mêmes structures, et répondent à de nombreux besoins pour le prétraitement des données et leur visualisation. Voici un exemple de code utilisant ce framework sur des données actuelles :
library(readr)
library(ggplot2)
library(dplyr)
library(tidyr)
read_csv2(filename) %>%
mutate(sexe = recode(sexe, `0` = "Total", `1` = "Hommes", `2` = "Femmes")) %>%
pivot_longer(cols = c(hosp, rea, rad, dc)) %>%
mutate(aggregation = ifelse(name %in% c("rad", "dc"),
"Nombre cumulé",
"Nombre actuel"
)) %>%
mutate(Personnes = recode(name,
dc = "décédées à l'hôpital",
hosp = "hospitalisées",
rad = "retournées à domicile",
rea = "en réanimation ou soins intensifs"
)) %>%
group_by(jour, Personnes, sexe, aggregation) %>%
summarise(value = sum(value)) %>%
ggplot(aes(x = jour, y = value, color = Personnes)) +
geom_line() +
facet_grid(cols = vars(sexe), rows = vars(aggregation)) +
theme(axis.title.y = element_blank())
En particulier, ggplot2 propose un système pour créer des graphiques complexes de manière déclarative (à opposer à la manière impérative couramment utilisée par les autres bibliothèques). Cette façon de procéder permet de mettre au premier plan la sémantique, c’est-à-dire le sens que l’on veut donner à la visualisation. On obtient ainsi à la fois des résultats graphiques avec un style cohérent, et un code clair, et ceci en utilisant un nombre d’instructions très restreint. Par exemple le code précédent (seules les 4 dernières lignes correspondent à la création du graphique, le reste étant du prétraitement) produit la figure suivante :
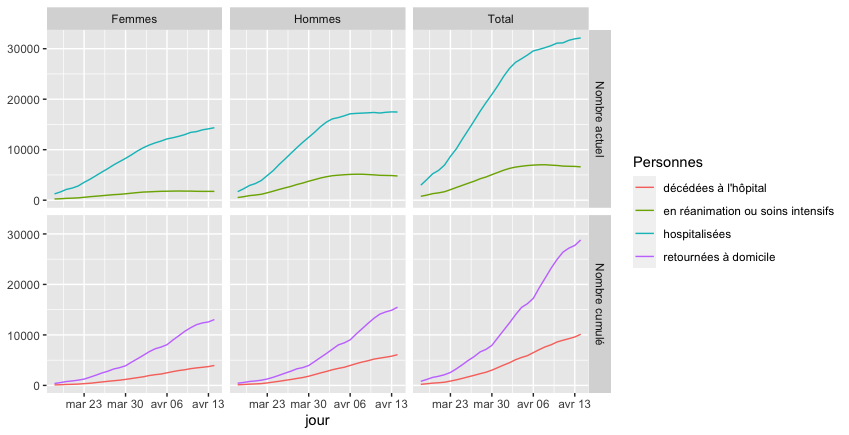
Évolution du nombre de personnes atteintes du COVID-19.
La visualisation est très importante pour analyser des données car elle permet de mieux les comprendre et ainsi de prendre les meilleurs décisions quant à la modélisation. Elle permet également de communiquer. R offre pour cela plusieurs outils intéressants. Par exemple, Leaflet permet de visualiser des données sur une carte interactive. R markdown permet de générer des rapports automatiquement mêlant du texte, des visualisations et des calculs appliqués aux données réelles. Les éléments constitutifs du rapport résultent de l’exécution de code R. On peut ainsi intégrer des graphiques générés à l’aide de ggplot2 directement dans le rapport, ou encore utiliser formattable pour mettre en évidence certaines valeurs d’un tableau. Le tableau suivant est produit à partir des mêmes données grâce à la bibliothèque “formattable” :
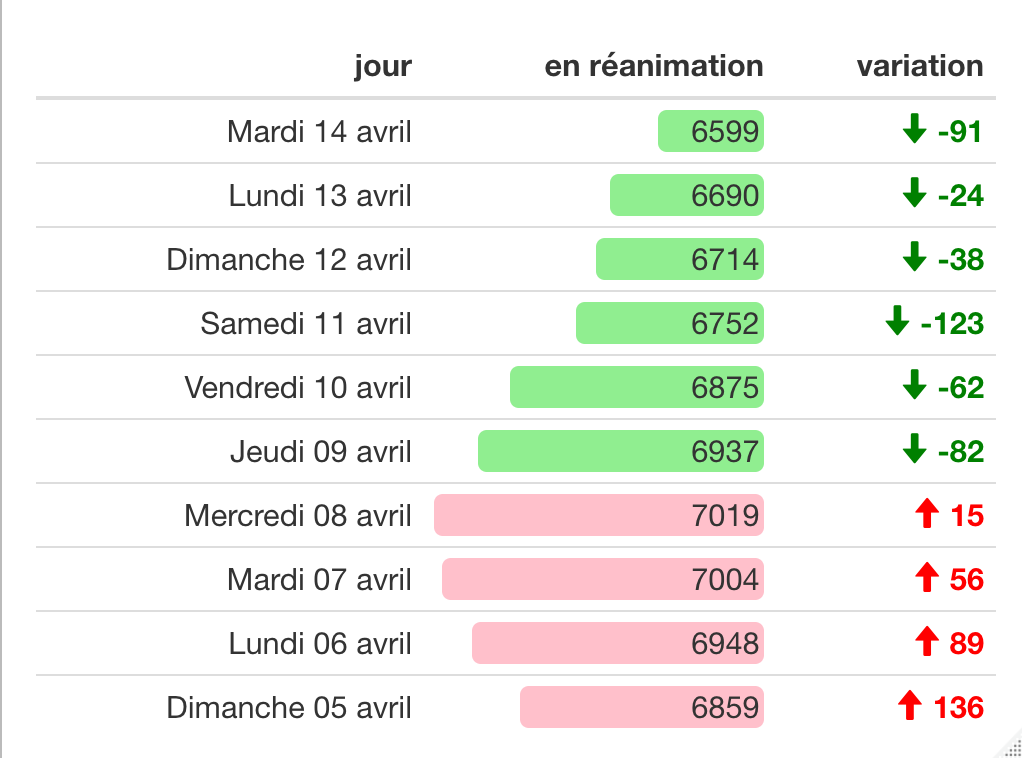
Évolution du nombre de patients atteints du COVID-19 en réanimation.
Pour la réalisation de POCs, la bibliothèque Shiny permet de réaliser une application interactive, démontrant ainsi aisément la création de valeur du POC sous une forme exploitable directement. Des frameworks à la mode tels que le framework de machine learning TensorFlow proposent une API pour le langage R. C’est aussi le cas par exemple pour du calcul distribué avec Spark qui peut être utilisé directement ou bien à travers un backend de dplyr optimisé : sparklyr. La richesse de l’écosystème se traduit par une profusion de packages sur les dépôts CRAN et Bioconductor. En particulier beaucoup d’implémentations de méthodes issues de la recherche ne trouvent pas leur pareil pour d’autres langages. Il serait donc dommage de s’en priver.
Des outils pour assurer la qualité du code
Vous êtes convaincu de l’intérêt de R pour développer rapidement un POC, mais pas (encore) pour une mise en production ? L’univers R dispose pourtant de nombreux outils pour garantir un code de qualité. Si ces outils sont malheureusement trop peu utilisés par des data scientists avec des profils non informaticiens, ils sont cependant bien présents :
- testthat est un framework de tests (unitaires, d’intégration, etc.) qui permet de garantir un bon fonctionnement à chaque instant du code d’un projet. shinytest facilite plus particulièrement la mise en place de tests pour les applications interactives développées avec Shiny.
- devtools est un ensemble d’outils pour aider à la création de packages. Créer un package permet de faciliter le déploiement d’un projet en spécifiant les dépendances, facilite son utilisation en intégrant une documentation, et accélère les développements en séparant les fonctionnalités en différents modules.
- renv aide à créer des environnements virtuels qui assurent l’isolation, la portabilité ainsi que la reproductibilité.
- miniCRAN permet de créer son propre dépôt de packages R.
- roxygen2 génère automatiquement la documentation à partir de commentaires définis dans le code source. Ceci permet d’avoir une documentation interactive intégrée à votre IDE.
- pkgdown facilite la création d’un site web pour présenter le projet, en incluant automatiquement la documentation générée par roxygen2.
Il est donc tout à fait possible de créer des applications rigoureusement avec R, en utilisant les mêmes méthodes et types d’outils que pour les autres langages utilisés classiquement en production. Voyons désormais quelques éléments importants pour l’intégration d’applications R au sein de votre SI.
Tout ce qu’il faut pour la création de micro services
Une application doit souvent pouvoir communiquer avec l’extérieur ou d’autres services. Si l’application expose une interface graphique (une application Shiny par exemple), il convient de la mettre derrière un proxy tel que Nginx.
On peut aussi décider de créer une API en R qui sera utilisée par un autre service. Pour cela, plumber permet de générer une API REST à partir de quelques commentaires spéciaux écrits au niveau des fonctions définies dans le code. Les fonctions ainsi décorées s’occupent de traiter les requêtes correspondant aux routes définies par ces commentaires comme dans l’exemple suivant :
#* Saluer une personne
#* @param nom Le nom de la personne à saluer
#* @get /hello
function(nom=""){
paste0("Bonjour ", nom)
}
Exemple d’utilisation de “plumber” permettant d’exécuter une fonction lors d’une requête GET sur la route /hello.
À l’inverse, il est aussi utile au sein de notre code R de faire appel à un autre service. Pour cela, httr permet d’appeler des API web, gérant ainsi si besoin l’authentification.
Entre services, il est parfois préférable d’utiliser des message brokers tels que RabbitMQ ou Kafka plutôt que de recourir à des API REST. De nombreuses bibliothèques R permettent de s’interfacer avec ces message brokers.
Il est à noter que la programmation asynchrone est tout à fait possible avec R, permettant ainsi de ne pas être bloqué par des entrées-sorties lentes. Un point aussi important à noter est que, compte tenu de l’utilisation d’un seul thread par R et donc l’utilisation pleine que d’un seul CPU, il convient de lancer plusieurs processus pour exploiter pleinement tous les CPUs (ceci n’est pas tout à fait vrai puisque certaines bibliothèques écrites en C++ peuvent exploiter plusieurs CPUs en utilisant des bibliothèques multi-threadées comme BLAS et LAPACK, mais c’est un point à avoir en tête pour la performance générale).
Python et R sur le même bateau
Si R est parfois considéré comme n’étant pas un vrai langage, cela résulte malheureusement de l’ignorance. En effet, R est un langage relativement complexe, en témoignent les nombreuses façons de définir des classes. Il peut être considéré comme faisant partie de la même catégorie que Python puisque partageant souvent les mêmes forces et les mêmes faiblesses : la richesse de l’écosystème en fait un langage de prédilection pour produire rapidement des résultats, mais la lenteur d’exécution nécessite parfois des contournements. Pour pallier cette lenteur, certaines fonctions qui méritent d’être optimisées sont implémentées en C++. Un profiling rigoureux permet d’éviter des goulots d’étranglements.
Témoin des challenges que doivent faire face R et Python, Hadley Wickham et Wes McKinney, les créateurs de dplyr et pandas respectivement, ont opté pour un travail commun sur des composants essentiels à la science de données. Cette complicité s’était traduite auparavant par la création d’un format d’échange de données tabulaires entre Python et R. Ceci permet notamment d’utiliser R et Python au cours d’une même session profitant ainsi des bibliothèques des deux écosystèmes. Ainsi nous sommes agnostiques au langage de programmation et exploitons pleinement les outils disponibles pour accélérer l’analyse des données, à l’instar de ce qui est présenté dans l’excellent livre Data Science at the Command Line.
Profitez de notre expérience
Vous avez un POC développé en R par vos data scientists et souhaitez le mettre en production ? Une réécriture complète n’est pas forcément nécessaire. Nous pouvons vous accompagner pour transformer votre code actuel en une application dans laquelle vous aurez confiance pour une mise en production.
Nous proposons également des formations ou un accompagnement pour une montée en compétences de vos équipes.
Enfin, nous pouvons toujours vous accompagner pour la réalisation de vos projets quelque soit la technologie à adopter. Qu’il s’agisse d’un changement de language pour satisfaire vos contraintes en termes de ressources et de politique, ou bien d’évolutions d’un code existant, notre expérience dans les diverses technologies data vous permettront de valoriser vos données.
